
Тестирование производительности языка Go в сетевых приложениях
В последнее время на хабре проскальзывало несколько постов посвященных языку программирования Go, но все они по большей части носили достаточно поверхностный и ознакомительных характер. Это натолкнуло меня на мысль провести более глубокое тестировани этого языка. Для начала пару слов почему меня заинтересовал именно этот язык, а не Python, Ruby, Java и тд. Основным языком разработки последние 4 годя для меня является PHP, и поэтому я давно чуствовал потребность в изучении языка который удовлетворял бы следующим критериям:
На мой взгляд Go идеально подходит под эти критерии — хотя я уверен у каждого из читателей будет свое мнение на эту тему. Python/Perl/<....> тоже идеально подходят для этого, но этот пост не о них. Так как язык Go привлек меня в первую очередь с точки зрения написания сетевых демонов, то и тестировать его я буду на сетевых задачах. В качестве тестовой задачи я выбрал написание echo демона работающего по websockets протоколу.
Другой важной особенностью языка Go о которой обычно забывают упоминуть — это реализация в нем легковесных процессов(как например в Erlang или OCaml). В теории это должно резко повысить масштабируемость сетевых приложений написанных на Go, но хотелось бы узнать как дело обстоит на самом деле.
И так приступим непосредственно к тестам. На удивление написание сервера не заняло много времни:
Все что от нас потребовалось это написать функцию обработчик соединения и использовать встроенную в Go реализацию websocket сервера. Для тестирования производительности новоиспеченного демона нам понадобиться клиент, который будет создавать для него нагрузку:
Как вы можете убедиться написание websocket клиента заняло еще меньше времени. Но запускать каждый тесты вручную и замерять время нехочтся, поэтому я использовал для этих целей встроенный в язык Go механизм юнит тестировния и профилирования. Для этого достаточно создать файл echoclient_test.go и написать в нем функции вида:
func TestEcho(t *testing.T) {} — для выполнения юнит тестирования и
func BenchmarkEcho(b *testing.B) {} — для выполнения профилирования соответсвенно.
Ниже исходный код функции которую я использовал для профилирования:
Теперь для того чтобы прогнать тесты нам достаточно запустить утилиту gotest и усказать ей регулярные выражения для выбора запускаемых тестов и бенчмарков. Несколько слов о том что же делает данный код — он одновременно запускает заданное количество легковесных потоков (goroutines), каждый из которых пингует наш echo сервер.
Остановлюсь немного подробнее на обработке ошибок. В Go она построена на основе 3-х встроенных функций — defer, recover и panic. Это аналог конструкции try… catch в других языках программирования, который позволяет поймать и обработать абсолютно любую ошибку. Ключевое defer говорит компилятору о том что данную функцию необходимо выполнить непосредственно при выходе из текущей функции, причем независимо от того каким образом завершилось ее выполнение — в результате какой-либо ошибки(panic) или обычным образом. Если исполнение функции завершилось в результате ошибки то мы можем восстановить нормальное выполнение программы путем вызова функции recover.
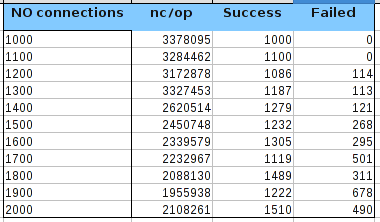
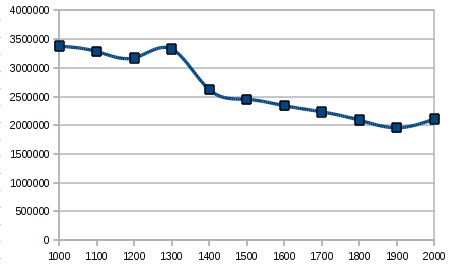
В первой колонке находиться количество одновременных соединений, вторая колонка — среднее время выполнения одного пинга в наносекундах, последующие — соответсвенно количество успешных и проваленных попыток. Ниже небольшой график зависимости среднего времени затрачиваемого на одно соединение от количества одновременных соединений:
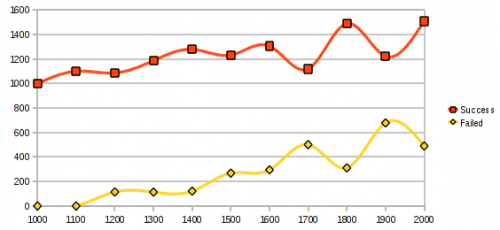
А также зависимость количества успешных/провальных попыток от количества одновременных соединений:
Немного об условиях проведения тестов:
И клиент и сервер запускались на одной и тойже машине, с весьма скромными характеристиками —
Intel® Pentium® Processor T2390 (1M Cache, 1.86 GHz, 533 MHz FSB), 2GB RAM.
Язык показал довольно высокую производительность в сетевых приложениях, но он еще недостаточно стабилен. В ходе проведения тестов обнаружилось что при нагрузке выше 1500 одновременных соединений сам сервер начал регулярно падать. Возможно дело в том что я исползовал 32 битный компилятор, в то время как основной разработчики считают именно 64 битную версию. Хочется верить что к моменту выхода протокола websockets в массы разработчики смогут довести язык Go до стабильности, достаточной для использования его в качестве основного языка для написания высоконагруженных websocket демонов.
- Быстрота. Уточню — не на 15-25% быстрее чем в PHP/Perl/Ruby (в хорошую погоду / с попутным ветром / в цикле вычисляющем число с тремя единичками/<добавьте свое условие>), а реально быстрее — в разы, а еще лучше на порядок быстрее чем популярные интерпретируемые языки.
- Простота написания. Да писать на C/C++ это круто, это для настоящих суровых программеров(а еще лучше взять и отдельные куски кода на asm переписать, чтобы «еще быстрее» стало), но этот путь не для меня.
- Удобство написания демонов. Конечно на их Perl/PHP тоже пишут… но я я думаю все согласяться что по надежности и стабильности работы они никогда не сравняться с аналогами написанными на C/C++.
На мой взгляд Go идеально подходит под эти критерии — хотя я уверен у каждого из читателей будет свое мнение на эту тему. Python/Perl/<....> тоже идеально подходят для этого, но этот пост не о них. Так как язык Go привлек меня в первую очередь с точки зрения написания сетевых демонов, то и тестировать его я буду на сетевых задачах. В качестве тестовой задачи я выбрал написание echo демона работающего по websockets протоколу.
Другой важной особенностью языка Go о которой обычно забывают упоминуть — это реализация в нем легковесных процессов(как например в Erlang или OCaml). В теории это должно резко повысить масштабируемость сетевых приложений написанных на Go, но хотелось бы узнать как дело обстоит на самом деле.
И так приступим непосредственно к тестам. На удивление написание сервера не заняло много времни:
//echod.go
package echod
import (
"http"
"io"
"websocket"
)
//Обработчик соединения
func EchoServer(ws *websocket.Conn) {
io.Copy(ws, ws)
}
func main() {
http.Handle("/echo", websocket.Handler(EchoServer))
err := http.ListenAndServe(":12345", nil)
if (err != nil) {
panic("ListenAndServe: " + err.String())
}
}Все что от нас потребовалось это написать функцию обработчик соединения и использовать встроенную в Go реализацию websocket сервера. Для тестирования производительности новоиспеченного демона нам понадобиться клиент, который будет создавать для него нагрузку:
//echoclient.go
package echoclient;
import (
"websocket"
"log"
)
func echo() {
ws, err := websocket.Dial("ws://localhost:12345/echo", "", "http://localhost/")
defer ws.Close()
if err != nil {
panic("Dial: " + err.String())
}
pingMsg := "Hello, echod!\n"
if _, err := ws.Write([]byte(pingMsg)); err != nil {
panic("Write: " + err.String())
}
var receivedMsg = make([]byte, len(pingMsg) + 1);
if n, err := ws.Read(receivedMsg); err != nil {
panic("Read: " + err.String())
} else {
receivedMsg = receivedMsg[0:n]
}
if receivedStr := string(receivedMsg); pingMsg != receivedStr {
log.Stdoutf("Strings not equal !%s!,!%s!, %i, %i ", pingMsg, receivedStr, len(receivedStr), len(pingMsg))
}
}
func main() {
echo()
}Как вы можете убедиться написание websocket клиента заняло еще меньше времени. Но запускать каждый тесты вручную и замерять время нехочтся, поэтому я использовал для этих целей встроенный в язык Go механизм юнит тестировния и профилирования. Для этого достаточно создать файл echoclient_test.go и написать в нем функции вида:
func TestEcho(t *testing.T) {} — для выполнения юнит тестирования и
func BenchmarkEcho(b *testing.B) {} — для выполнения профилирования соответсвенно.
Ниже исходный код функции которую я использовал для профилирования:
package echoclient;
import (
"testing"
)
//Функция используемая для запуска echo клиента в отдельном процессе
func echoRoutine(c chan int, index int) {
//Обработка ошибок, об этом подробнее ниже по тексту
defer func() {
//проверяем была ли какая-нибуть ошибка
if err := recover(); err != nil {
print("Routine failed:", err, "\n")
c <- -index
} else {
c <- index
print("Exit go routine\n")
}
}()
echo()
}
// Непосредственно сам бенчмарк
func BenchmarkCSP(b *testing.B) {
//b.N = 2000; - если нужно подсказываем профилировщику сколько раз мы хотим прогнать тест
// канал используемый для синхронизации потоков
c := make(chan int)
for i:= 0; i < b.N; i++ {
// запускаем каждый клиент в отдельной goroutine
go echoRoutine(c, i)
}
print("Fork all routines \n")
var (
success, failed int
)
for i:= 0; i < b.N; i++ {
//ждем когда поток вернет результат выполнения
// если он отрицательный тест провален, если положительный соответсвенно выполнен
index := <- c
if index < 0 {
failed++
print(i, ". Goroutine failed:", -index, "\n")
} else {
success++
print(i, ". Goroutine:", index, "\n")
}
}
print("Totals, success:", success," failed: ", failed, " \n")
}Теперь для того чтобы прогнать тесты нам достаточно запустить утилиту gotest и усказать ей регулярные выражения для выбора запускаемых тестов и бенчмарков. Несколько слов о том что же делает данный код — он одновременно запускает заданное количество легковесных потоков (goroutines), каждый из которых пингует наш echo сервер.
Остановлюсь немного подробнее на обработке ошибок. В Go она построена на основе 3-х встроенных функций — defer, recover и panic. Это аналог конструкции try… catch в других языках программирования, который позволяет поймать и обработать абсолютно любую ошибку. Ключевое defer говорит компилятору о том что данную функцию необходимо выполнить непосредственно при выходе из текущей функции, причем независимо от того каким образом завершилось ее выполнение — в результате какой-либо ошибки(panic) или обычным образом. Если исполнение функции завершилось в результате ошибки то мы можем восстановить нормальное выполнение программы путем вызова функции recover.
Результаты тестов
В первой колонке находиться количество одновременных соединений, вторая колонка — среднее время выполнения одного пинга в наносекундах, последующие — соответсвенно количество успешных и проваленных попыток. Ниже небольшой график зависимости среднего времени затрачиваемого на одно соединение от количества одновременных соединений:
А также зависимость количества успешных/провальных попыток от количества одновременных соединений:
Немного об условиях проведения тестов:
И клиент и сервер запускались на одной и тойже машине, с весьма скромными характеристиками —
Intel® Pentium® Processor T2390 (1M Cache, 1.86 GHz, 533 MHz FSB), 2GB RAM.
Выводы
Язык показал довольно высокую производительность в сетевых приложениях, но он еще недостаточно стабилен. В ходе проведения тестов обнаружилось что при нагрузке выше 1500 одновременных соединений сам сервер начал регулярно падать. Возможно дело в том что я исползовал 32 битный компилятор, в то время как основной разработчики считают именно 64 битную версию. Хочется верить что к моменту выхода протокола websockets в массы разработчики смогут довести язык Go до стабильности, достаточной для использования его в качестве основного языка для написания высоконагруженных websocket демонов.